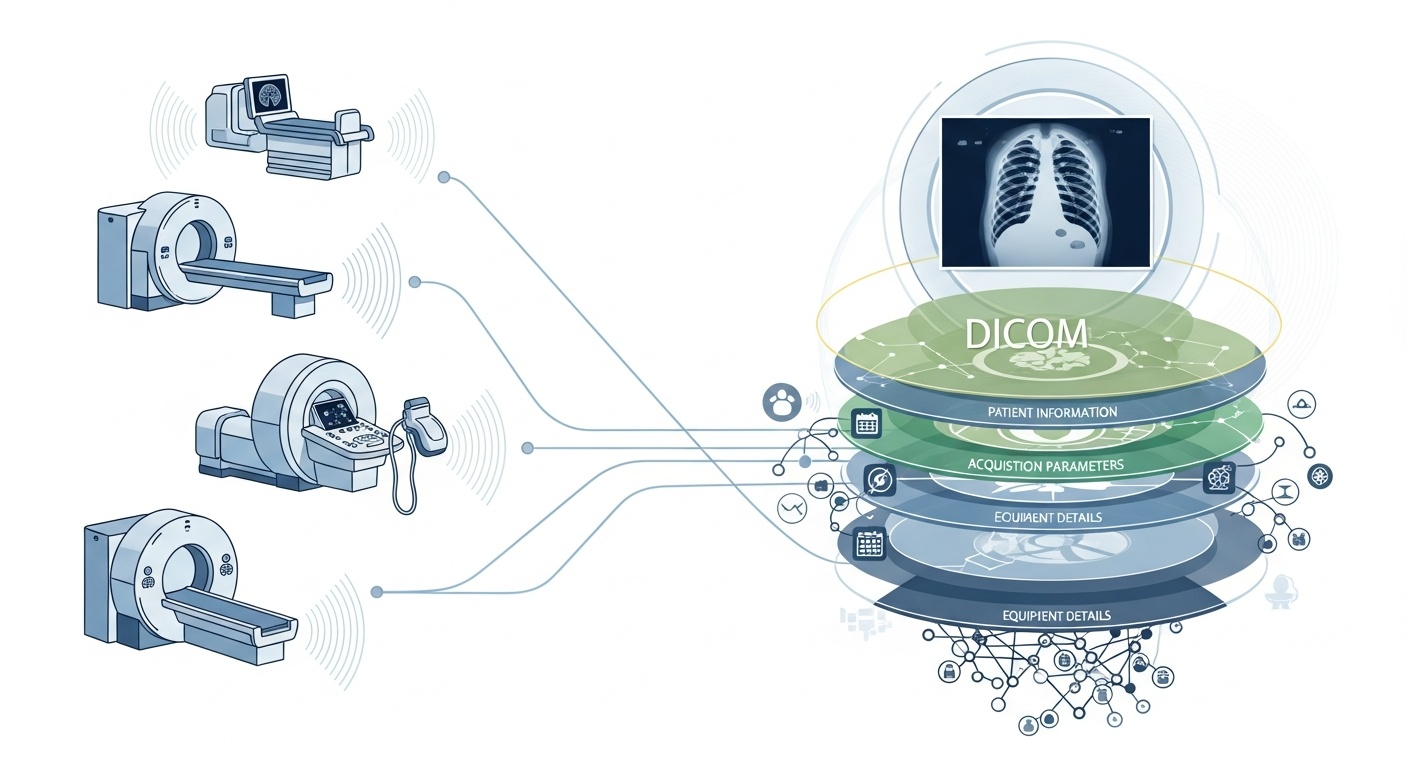
Jedes Mal, wenn ein Radiologieteam einen Patienten scannt, z. B. CT, MRT oder Ultraschall, wird eine Kaskade von Daten erzeugt. Am sichtbarsten ist das Bild selbst, aber dahinter verbirgt sich eine reichhaltige Schicht von Metadaten: das Wer, Was, Wann, Wie und Wo des Scans. Diese Schicht wird durch den Standard DICOM (Digital Imaging and Communications in Medicine) geregelt, einen Standard für das medizinische Bildformat, der von der National Electrical Manufacturers Association (NEMA) und dem American College of Radiology (ACR) vor Jahrzehnten festgelegt wurde.
Was die Metadaten so interessant macht, ist, dass sie strukturiert, maschinenlesbar und bemerkenswert detailliert sind: Geräteeinstellungen, Erfassungsparameter, Patientendemografie, Studien-IDs, sogar Institutionscodes und Details zum Hersteller der Modalität. Dieser Reichtum ermöglicht Big-Data-Analysen, nachgelagerte Forschung, KI-Modellierung und Protokollstandardisierung, wenn man ihn gut nutzt.
Im Kontext von Big Data sprechen wir nicht nur über ein paar Dutzend bildgebende Studien. Wir sprechen von Hunderttausenden oder sogar Millionen von Bildern über Modalitäten, Standorte und Anbieter hinweg, mit Metadaten als zentrale Indexierungsschicht: das „Wer & Wann & Wie“ jedes Elements. Ohne die effektive Nutzung von Metadaten riskieren Sie, ein riesiges Archiv von Bildern zu haben, aber nur minimale Möglichkeiten, diese abzufragen, zu vergleichen oder Erkenntnisse daraus abzuleiten. Ein aktueller Bericht stellt fest: „Der Großteil der in PACS-Archiven gespeicherten Informationen wird nie wieder abgerufen“, eine vergebene Chance.
Angenommen, Sie führen eine standortübergreifende Studie mit Lungen-CT-Scans zur Früherkennung von Emphysemen durch. Sie möchten Scans basierend auf Parametern auswählen: Scanner-Anbieter/Marke/Modell, Schichtdicke, Rekonstruktionskernel, Patientenalter, Datumsbereiche, vielleicht sogar Dosisparameter. Die meisten davon sind Metadatenfelder, keine Pixeldaten. Das Extrahieren dieser Tags ermöglicht es Ihnen, die Kohorte aufzubauen, inkompatible Scans auszuschließen (z. B. zu dicke Schichten) und Vergleichbarkeit sicherzustellen.
Metadaten ermöglichen es Ihnen, den Bildgebungsprozess selbst zu überwachen: Verwendet die Institution das korrekte Protokoll? Weichen Erfassungsparameter im Laufe der Zeit ab (z. B. Sichtfeld, Zeitpunkt der Kontrastmittelinjektion)? Sind die Anbietereinstellungen konsistent? In einer Big-Data-Welt, in der täglich tausende von Scans stattfinden, können Sie sich nicht auf eine manuelle Sichtprüfung verlassen. Sie benötigen Analysen auf Basis von Metadaten. Viele PACS-Systeme nutzen Metadaten aus diesem Grund unzureichend.
Wenn Sie eine KI- oder Radiomics-Pipeline aufbauen, können Sie nicht jedes Bild als austauschbar betrachten. Metadaten werden zu einer integralen Kontrollvariable: Eingabemerkmale umfassen oft Modalität, kVp (Kilovoltage Peak), Hersteller, Kernel, Schichtdicke, und sogar das Datum oder das Krankenhaus können wichtig sein (Domain Shift). Diese Metadatenfelder helfen, Verzerrungen (Bias) zu managen, Daten zu harmonisieren und Bilder mit Kontext zu annotieren. Viele Forscher bezeichnen Metadaten als „genauso wichtig wie Pixeldaten“.
Big Data bedeutet Skalierung. Das impliziert unterschiedliche Quellen, mehrere Anbieter, verschiedene Institutionen und heterogene Formate. DICOM-Metadaten sind die standardisierte „Sprache“, die hilft, die Metadatenschicht zu vereinheitlichen, Suche/Indexierung zu ermöglichen, Interoperabilität sicherzustellen und skalierbare Architekturen (Cloud-PACS, föderierte Archive) aufzubauen. Aber die Implementierung ist entscheidend. Die gleiche PMC-Studie fand heraus, dass viele Systeme den Standard nicht vollständig ausschöpfen.
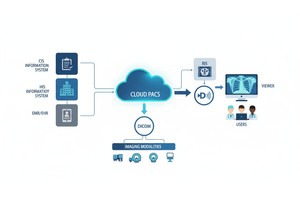
PostDICOM bietet ein Cloud-basiertes PACS (Picture Archiving and Communication System) zum Speichern, Anzeigen und Teilen von Bildgebungsstudien und klinischen Dokumenten. Einige wichtige metadaten-relevante Funktionen von PostDICOM:
• Unterstützung für DICOM-Tags & Beschreibungen: Unsere Ressourcenbibliothek listet „DICOM-Modalität & Tags“ auf, was Nutzern den Zugriff auf Tag-Listen und Beschreibungen ermöglicht.DICOM-Modalität & Tags
• API / FHIR-Integration: Es werden API- und FHIR-Schnittstellen (Fast Healthcare Interoperability Resources) unterstützt, wodurch Metadaten programmatisch abgefragt, in andere Systeme integriert und analysiert werden können.
• Cloud-Skalierbarkeit & standortübergreifender Austausch: Das Teilen zwischen Patienten, Ärzten und Institutionen sowie unbegrenzte Skalierbarkeit machen Big-Data-Pipelines realisierbar.
• Erweiterte Bildverarbeitung & Unterstützung mehrerer Modalitäten: Während dies Pixel betrifft, bedeutet die Unterstützung von Modalitäten wie PET-CT und Multi-Serien, dass die Metadaten substanziell sind (SUV-Werte, Fusionsvolumen, Modalitätstyp) und für Analysen verfügbar sind.
Die Verwendung einer Plattform wie PostDICOM ermöglicht es Ihnen, Metadaten durch strukturierte Workflows, APIs und Cloud-Architektur nutzbar zu machen.
So strukturieren Sie den Workflow von Roharchiven bis zu analysebereiten Erkenntnissen.
 - Created by PostDICOM.jpg)
Der erste Schritt zur Nutzung von DICOM-Metadaten für Analysen ist die Extraktion und Normalisierung. Bibliotheken wie das Open-Source-Python-Paket PyDicom werden häufig verwendet, um DICOM-Dateien zu parsen und relevante Tags zu extrahieren, einschließlich Bildzeilen und -spalten, Faltungskernen und modalitätsspezifischen Erfassungsparametern.
Der Umgang mit Heterogenität ist entscheidend, da verschiedene Anbieter oft private Tags oder nicht standardisierte Implementierungen verwenden. Robustes Parsing, Fallback-Logik und umfassende Tag-Zuordnungstabellen sind erforderlich, um Konsistenz über Datensätze hinweg sicherzustellen.
Nach der Extraktion müssen die Metadaten normalisiert und auf Standard-Ontologien und -Strukturen abgebildet werden, wie z. B. Modalitätscodes, Anbieternamen, Schichtdickenkategorien sowie standardisierte Datums- und Zeitformate.
Schließlich sollten die strukturierten Metadaten in einer Big-Data-Umgebung gespeichert werden, wie z. B. einer relationalen Datenbank, einem NoSQL-Speicher oder einem spaltenbasierten Data Lake, mit Indexierung, um schnelle und effiziente Abfragen zu ermöglichen.
Nach der Extraktion müssen Metadaten einer Qualitätssicherung unterzogen werden, um Genauigkeit und Zuverlässigkeit zu gewährleisten. Fehlende oder inkonsistente Felder, wie leere Schichtdickenwerte, inkonsistente Modalitätsbezeichnungen oder doppelte Studien-Instanz-UIDs, müssen identifiziert und korrigiert werden.
Datenschutz und Anonymisierung sind in dieser Phase ebenfalls kritisch, da Metadaten oft personenbezogene Daten enthalten, einschließlich Patientennamen, IDs und Daten; De-Identifizierungs-Tools und Protokolle sind unerlässlich.
Die Aufrechterhaltung umfassender Audit-Trails ist eine weitere wichtige Praxis, die dokumentiert, wann Metadaten extrahiert wurden, welche Parser-Versionen verwendet wurden und welche Fehler während des Prozesses aufgetreten sind.
Governance-Richtlinien sollten auch Pflichtfelder definieren und Anleitungen zum Umgang mit älteren oder unvollständigen Datensätzen bieten, um sicherzustellen, dass nachgelagerte Analysen genau und konform sind.
Der nächste Schritt ist die metadaten-gesteuerte Indexierung und das Feature Engineering, wodurch Rohmetadaten in umsetzbare Informationen umgewandelt werden.
Dies beinhaltet das Erstellen von Indizes und Filtern, die es Forschern und Analysten ermöglichen, spezifische Datensätze abzufragen, zum Beispiel alle Thorax-CT-Scans mit einer Schichtdicke unter 1,5 Millimetern von einem bestimmten Anbieter innerhalb eines bestimmten Datumsbereichs abzurufen.
Feature Engineering baut darauf auf, indem Metadatenfelder wie Anbieter, Modell, Erfassungsdatum, Schichtdicke, Faltungskernel, Kontrastmittelprotokoll, Körperregion, Strahlendosis und Institutions-ID zu strukturierten Variablen kombiniert werden, die für die Analyse geeignet sind.
Metadaten können auch mit klinischen Datensätzen verknüpft werden, wodurch Bilddaten mit Patientenergebnissen, Diagnosen oder Behandlungen verbunden werden. Diese Verknüpfung ermöglicht eine ganzheitlichere Sicht auf Bilddaten und deren klinischen Kontext.
Sobald Metadaten indexiert und Features entwickelt sind, werden Analytik und die Generierung von Erkenntnissen möglich.
Deskriptive Analytik kann Studienvolumina nach Modalität, Anbieter oder Region aufzeigen, Trends bei Erfassungsparametern verfolgen und Fehler oder Inkonsistenzen in Bildgebungspraktiken hervorheben. Vergleichende Analytik ermöglicht die Bewertung von Erfassungsprotokollen über Institutionen hinweg, die Erkennung von Abweichungen und die Identifizierung von Ausreißer-Scans, die besondere Aufmerksamkeit erfordern könnten.
Für maschinelles Lernen und KI-Anwendungen sind Metadaten unerlässlich, um Domain Shift zu kontrollieren, sicherzustellen, dass Trainings- und Testdatensätze angemessen stratifiziert sind, und pixelbasierte Merkmale mit strukturierten Metadatenvariablen zu kombinieren. Operative Dashboards können diese Daten dann nutzen, um die Arbeitslast zu überwachen, Qualitätssicherungskennzahlen zu bewerten und die Protokollkonformität an allen Standorten sicherzustellen.
Schließlich schließen Feedback und kontinuierliche Verbesserung den Metadaten-Lebenszyklus ab. Erkenntnisse aus Analysen können die Verfeinerung von Erfassungsprotokollen und die Standardisierung von Arbeitsabläufen informieren, um die allgemeine Datenqualität zu verbessern.
Neue Bildgebungsstudien und Metadaten sollten kontinuierlich eingepflegt werden, unter Überwachung der Leistung des Metadatenspeichers, der Abfragezeiten und der Datenintegrität. Gewonnene Erkenntnisse sollten archiviert werden, um prädiktive Metadatenfelder zu erfassen, wiederkehrende Lücken oder Fehler zu beheben und Governance-Praktiken zu verbessern.
Dieser iterative Ansatz stellt sicher, dass Metadaten-Pipelines robust, skalierbar und wertvoll für zukünftige Forschung, KI-Anwendungen und operative Entscheidungsfindung bleiben.
• Variabilität bei Anbietern/Institutionen: Private Tags oder lockere Interpretation von Standards.
• Fehlende oder beschädigte Metadaten: Ältere Studien können unvollständige Header aufweisen.
• Datenschutz & Anonymisierung: PHI (Protected Health Information) muss für standortübergreifende Forschung unkenntlich gemacht werden.
• Skalierung & Leistung: Millionen von Bildern erfordern effiziente Verarbeitung und Speicherung.
• Domain Shift/Verzerrung: Dominante Anbieter/Protokolle können KI-Modelle verzerren.
• Regulatorische & Compliance-Fragen: Einsätze in mehreren Regionen können HIPAA, DSGVO oder lokale Vorschriften betreffen.
DICOM-Metadaten sind das verborgene Gerüst der Bildgebungsanalytik. Plattformen wie PostDICOM veranschaulichen, wie man ein fragmentiertes Archiv von DICOM-Dateien in ein durchsuchbares, skalierbares und metadaten-gesteuertes Ökosystem verwandelt. Wenn Sie PostDICOM erkunden möchten, empfehlen wir Ihnen, unsere kostenlose 7-Tage-Testversion zu nutzen.
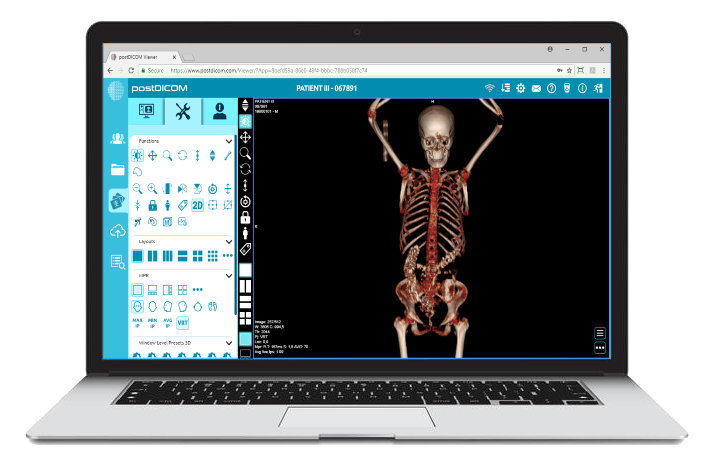
|
Cloud PACS und Online DICOM-ViewerLaden Sie DICOM-Bilder und klinische Dokumente auf PostDICOM-Server hoch. Speichern, betrachten, zusammenarbeiten und teilen Sie Ihre medizinischen Bilddateien. |