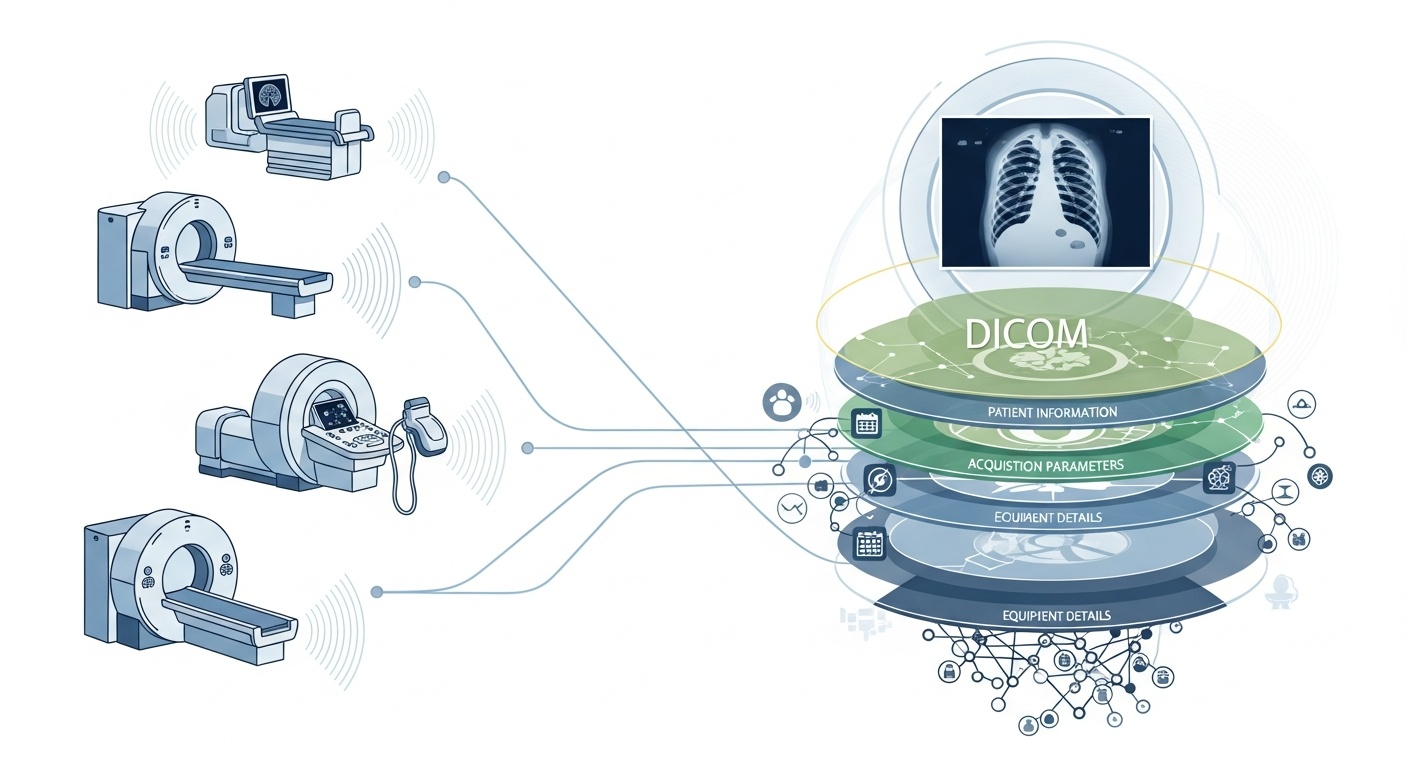
Cada vez que un equipo de radiología escanea a un paciente, digamos una TC, RM o ecografía, se genera una cascada de datos. Lo más visible es la imagen en sí, pero detrás de ella hay una rica capa de metadatos: el quién, qué, cuándo, cómo y dónde del escaneo. Esa capa se rige por el estándar DICOM (Imágenes Digitales y Comunicaciones en Medicina), un estándar de formato de imágenes médicas establecido por la Asociación Nacional de Fabricantes Eléctricos (NEMA) y el Colegio Americano de Radiología (ACR) hace décadas.
Lo que hace que los metadatos sean tan interesantes es que son estructurados, legibles por máquina y notablemente detallados: configuraciones del equipo, parámetros de adquisición, demografía del paciente, IDs del estudio, e incluso códigos de la institución y detalles del fabricante de la modalidad. Esa riqueza es lo que permite la analítica de big data, la investigación posterior, el modelado de IA y la estandarización de protocolos si se aprovecha bien.
En el contexto del big data, no estamos hablando solo de unas pocas docenas de estudios de imagen. Estamos hablando de cientos de miles, o incluso millones, de imágenes a través de modalidades, sitios y proveedores, con los metadatos como la capa clave de indexación: el "quién, cuándo y cómo" de cada ítem. Sin utilizar eficazmente los metadatos, se arriesga a tener un archivo masivo de imágenes pero una capacidad mínima para consultar, comparar o derivar perspectivas de ellos. Una revisión reciente afirma: "la mayoría de la información almacenada en archivos PACS nunca se vuelve a acceder," una oportunidad desperdiciada.
Digamos que está llevando a cabo un estudio multi-sitio de escaneos de TC de pulmón para la detección temprana de enfisema. Querrá seleccionar escaneos basados en parámetros: proveedor/marca/modelo del escáner, grosor de corte, kernel de reconstrucción, edad del paciente, rangos de fechas, quizás incluso parámetros de dosis. La mayoría de esos son campos de metadatos, no datos de píxeles. Extraer esas etiquetas le permite construir la cohorte, excluir escaneos incompatibles (ej., cortes demasiado gruesos) y asegurar la comparabilidad.
Los metadatos le permiten monitorear el proceso de imagenología en sí: ¿está la institución utilizando el protocolo correcto? ¿Están desviándose los parámetros de adquisición con el tiempo (ej., campo de visión, tiempo de inyección de contraste)? ¿Son consistentes las configuraciones del proveedor? En un mundo de big data donde ocurren miles de escaneos por día, no puede confiar en la inspección visual humana. Necesita analítica sobre los metadatos. Muchos sistemas PACS subexplotan los metadatos por esta razón.
Si construye un pipeline de IA o radiómica, no puede tratar cada imagen como intercambiable. Los metadatos se convierten en una variable de control integral: las características de entrada a menudo incluyen modalidad, kVp (pico de kilovoltaje), fabricante, kernel, grosor de corte, e incluso la fecha o el hospital pueden importar (cambio de dominio). Estos campos de metadatos ayudan a gestionar el sesgo, armonizar datos y anotar imágenes con contexto. Muchos investigadores llaman a los metadatos "tan importantes como los datos de píxeles."
Big data significa escala. Eso implica fuentes variadas, múltiples proveedores, diferentes instituciones y formatos heterogéneos. Los metadatos DICOM son el "lenguaje" estandarizado que ayuda a unificar la capa de metadatos, permitir la búsqueda/indexación, asegurar la interoperabilidad y construir arquitecturas escalables (Cloud PACS, archivos federados). Pero la implementación importa. El mismo estudio de PMC encontró que muchos sistemas no explotan completamente el estándar.
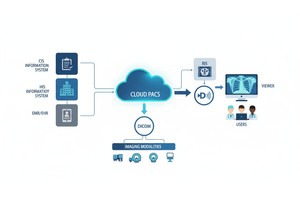
PostDICOM ofrece un PACS basado en la nube (Sistema de Archivo y Comunicación de Imágenes) para almacenar, visualizar y compartir estudios de imagen y documentos clínicos. Algunas características clave de PostDICOM relevantes para los metadatos:
• Soporte para Etiquetas y Descripciones DICOM: Nuestra biblioteca de recursos lista "Modalidad y Etiquetas DICOM", permitiendo a los usuarios acceder a listas de etiquetas y descripciones.Modalidad y Etiquetas DICOM
• Integración API / FHIR: Soporta interfaces API y FHIR (Recursos de Interoperabilidad en Salud Rápida), permitiendo que los metadatos sean consultados programáticamente, integrados con otros sistemas y analizados.
• Escalabilidad en la Nube e Intercambio Multi-sitio: Intercambio entre pacientes, médicos, instituciones; la escalabilidad ilimitada significa que los pipelines de big data se vuelven factibles.
• Procesamiento Avanzado de Imágenes y Soporte Multi-modalidad: Si bien esto concierne a los píxeles, el soporte de modalidades como PET–CT y multi-series significa que los metadatos son sustanciales (valores SUV, volúmenes de fusión, tipo de modalidad) y están disponibles para analítica.
Usar una plataforma como PostDICOM le permite aprovechar los metadatos a través de flujos de trabajo estructurados, APIs y arquitectura en la nube.
Aquí se explica cómo estructurar el flujo de trabajo desde los archivos brutos hasta perspectivas listas para analítica.
 - Created by PostDICOM.jpg)
El primer paso para aprovechar los metadatos DICOM para analítica es la extracción y normalización. Bibliotecas como el paquete de código abierto en Python PyDicom se usan comúnmente para analizar archivos DICOM y extraer etiquetas relevantes, incluyendo filas y columnas de imagen, kernels de convolución y parámetros de adquisición específicos de la modalidad.
Manejar la heterogeneidad es crucial, ya que diferentes proveedores a menudo usan etiquetas privadas o implementaciones no estándar. Se requiere un análisis robusto, lógica de respaldo y tablas de mapeo de etiquetas completas para asegurar la consistencia a través de los conjuntos de datos.
Una vez extraídos, los metadatos deben ser normalizados y mapeados a ontologías y estructuras estándar, como códigos de modalidad, nombres de proveedores, categorías de grosor de corte y formatos estandarizados de fecha y hora.
Finalmente, los metadatos estructurados deben almacenarse en un entorno de big data, como una base de datos relacional, almacenamiento NoSQL o lago de datos en columnas, con indexación para permitir consultas rápidas y eficientes.
Una vez extraídos, los metadatos deben someterse a garantía de calidad para asegurar precisión y fiabilidad. Campos faltantes o inconsistentes, como valores de grosor de corte en blanco, etiquetas de modalidad inconsistentes o UIDs de Instancia de Estudio duplicados, necesitan ser identificados y corregidos.
La privacidad y la anonimización también son críticas en esta etapa, ya que los metadatos a menudo contienen información personalmente identificable incluyendo nombres de pacientes, IDs y fechas; las herramientas y protocolos de desidentificación son esenciales.
Mantener pistas de auditoría completas es otra práctica importante, documentando cuándo se extrajeron los metadatos, qué versiones de analizador se usaron y cualquier error encontrado durante el proceso.
Las políticas de gobernanza también deben definir campos obligatorios y proporcionar orientación sobre cómo manejar conjuntos de datos heredados o incompletos para asegurar que la analítica posterior sea precisa y conforme.
El siguiente paso es la indexación e ingeniería de características impulsadas por metadatos, lo cual transforma los metadatos brutos en información procesable.
Esto implica crear índices y filtros que permitan a investigadores y analistas consultar conjuntos de datos específicos, por ejemplo, recuperar todos los escaneos de TC de tórax con grosor de corte inferior a 1.5 milímetros de un proveedor particular dentro de un rango de fechas dado.
La ingeniería de características se basa en esto combinando campos de metadatos como proveedor, modelo, fecha de adquisición, grosor de corte, kernel de convolución, protocolo de contraste, región corporal, dosis de radiación e ID de institución en variables estructuradas adecuadas para el análisis.
Los metadatos también pueden vincularse a conjuntos de datos clínicos, conectando datos de imágenes con resultados de pacientes, diagnósticos o tratamientos. Esta vinculación permite una visión más holística de los datos de imágenes y su contexto clínico.
Una vez que los metadatos están indexados y las características están diseñadas, la analítica y la generación de perspectivas se vuelven posibles.
La analítica descriptiva puede revelar volúmenes de estudio por modalidad, proveedor o región, rastrear tendencias en parámetros de adquisición y resaltar errores o inconsistencias en prácticas de imagenología. La analítica comparativa permite la evaluación de protocolos de adquisición a través de instituciones, detección de desviaciones e identificación de escaneos atípicos que pueden requerir atención especial.
Para aplicaciones de aprendizaje automático e IA, los metadatos son esenciales para controlar el cambio de dominio, asegurando que los conjuntos de datos de entrenamiento y prueba se estratifiquen apropiadamente, y combinando características basadas en píxeles con variables de metadatos estructurados. Los tableros operativos pueden luego aprovechar estos datos para monitorear la carga de trabajo, evaluar métricas de garantía de calidad y asegurar el cumplimiento del protocolo a través de los sitios.
Finalmente, la retroalimentación y la mejora continua completan el ciclo de vida de los metadatos. Las perspectivas derivadas de la analítica pueden informar el refinamiento de los protocolos de adquisición y la estandarización de flujos de trabajo para mejorar la calidad general de los datos.
Nuevos estudios de imagen y metadatos deben ser ingeridos continuamente, con monitoreo del rendimiento del almacén de metadatos, tiempos de consulta e integridad de datos. Las lecciones aprendidas deben archivarse para capturar campos de metadatos predictivos, abordar brechas o errores recurrentes y mejorar las prácticas de gobernanza.
Este enfoque iterativo asegura que los pipelines de metadatos permanezcan robustos, escalables y valiosos para futuras investigaciones, aplicaciones de IA y toma de decisiones operativas.
• Variabilidad de proveedor/institución: Etiquetas privadas o interpretaciones sueltas del estándar.
• Metadatos faltantes o corruptos: Los estudios más antiguos pueden tener encabezados incompletos.
• Privacidad de Datos y Anonimización: La PHI debe ser desidentificada para investigación multi-sitio.
• Escala y Rendimiento: Millones de imágenes requieren procesamiento y almacenamiento eficiente.
• Cambio de dominio/sesgo: Los proveedores/protocolos dominantes pueden sesgar los modelos de IA.
• Cuestiones Regulatorias y de Cumplimiento: Los despliegues multi-región pueden involucrar HIPAA, GDPR o regulaciones locales.
Los metadatos DICOM son el esqueleto oculto de la analítica de imágenes. Plataformas como PostDICOM ilustran cómo transformar un archivo fragmentado de archivos DICOM en un ecosistema impulsado por metadatos, buscable y escalable. Si desea explorar PostDICOM, le animamos a obtener nuestra prueba gratuita de 7 días.
|
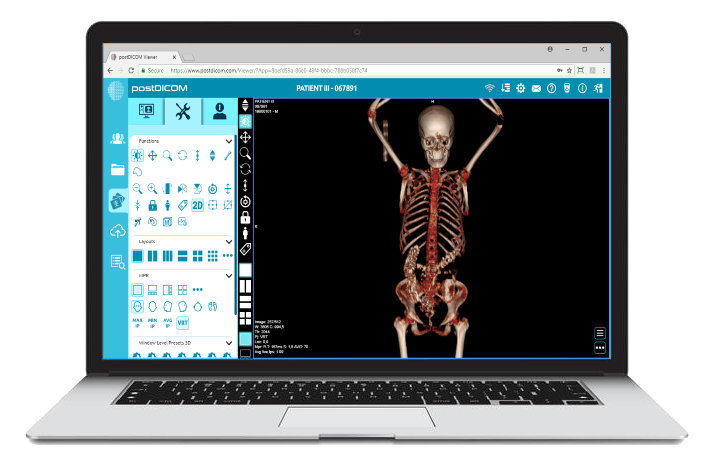
Cloud PACS y Visor DICOM en LíneaSuba imágenes DICOM y documentos clínicos a los servidores de PostDICOM. Almacene, visualice, colabore y comparta sus archivos de imagenología médica. |