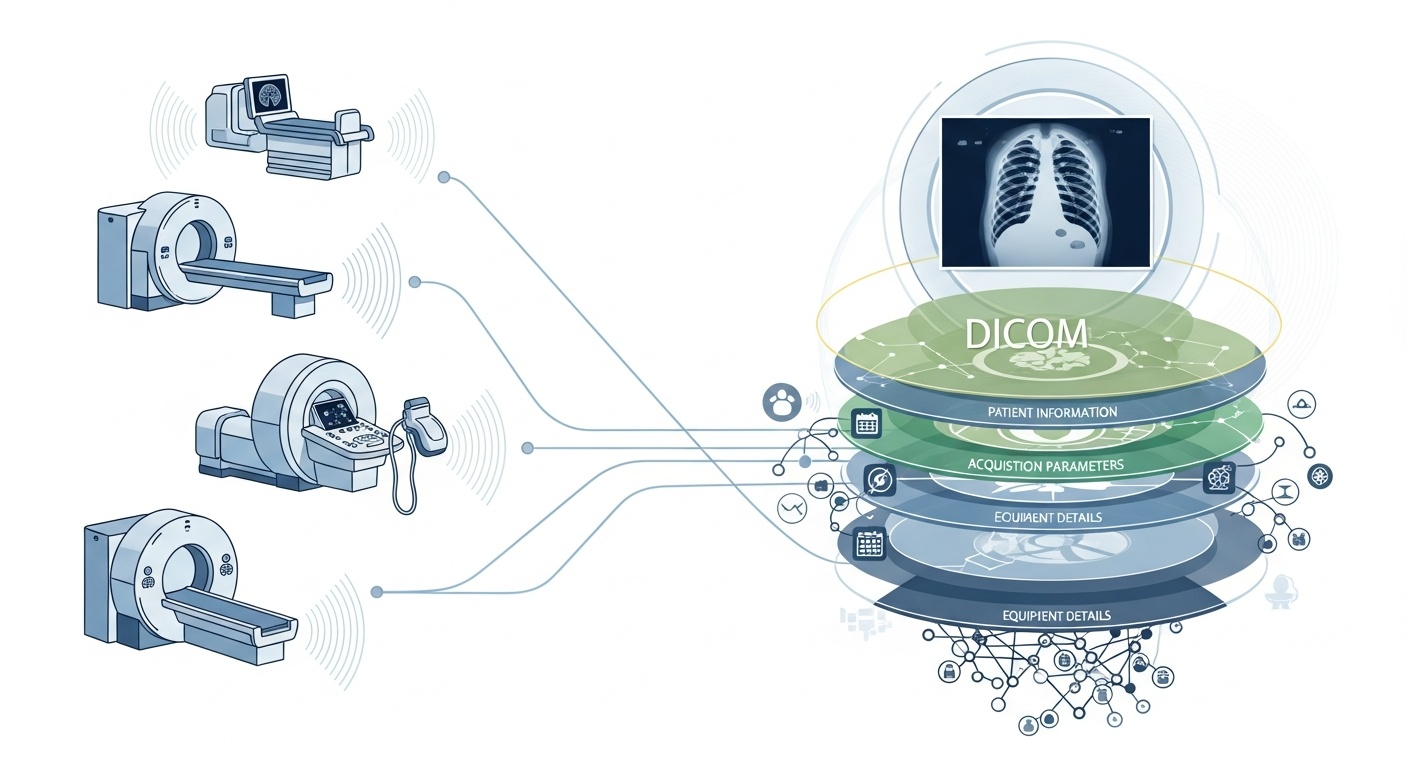
Chaque fois qu'une équipe de radiologie examine un patient, par exemple par scanner (CT), IRM ou échographie, une cascade de données est générée. L'élément le plus visible est l'image elle-même, mais derrière elle se cache une riche couche de métadonnées : le qui, quoi, quand, comment et où de l'examen. Cette couche est régie par la norme DICOM (Digital Imaging and Communications in Medicine), une norme de format d'imagerie médicale établie par la National Electrical Manufacturers Association (NEMA) et l'American College of Radiology (ACR) il y a plusieurs décennies.
Ce qui rend les métadonnées si intéressantes, c'est qu'elles sont structurées, lisibles par machine et remarquablement détaillées : réglages de l'équipement, paramètres d'acquisition, démographie du patient, identifiants d'étude, et même codes de l'institution et détails du fabricant de la modalité. Cette richesse est ce qui permet l'analyse du Big Data, la recherche en aval, la modélisation par IA et la normalisation des protocoles si vous l'exploitez bien.
Dans le contexte du Big Data, nous ne parlons pas seulement de quelques douzaines d'études d'imagerie. Nous parlons de centaines de milliers, voire de millions d'images à travers les modalités, les sites et les fournisseurs, avec les métadonnées comme couche d'indexation clé : le « qui, quand et comment » de chaque élément. Sans utiliser efficacement les métadonnées, vous risquez d'avoir une archive massive d'images mais une capacité minimale à les interroger, les comparer ou en tirer des informations. Une revue récente déclare : « la majorité des informations stockées dans les archives PACS ne sont jamais consultées à nouveau », une occasion manquée.
Supposons que vous meniez une étude multi-sites sur des scanners pulmonaires pour la détection précoce de l'emphysème. Vous voudrez sélectionner des scanners basés sur des paramètres : fournisseur/marque/modèle du scanner, épaisseur de coupe, noyau de reconstruction, âge du patient, plages de dates, peut-être même paramètres de dose. La plupart de ceux-ci sont des champs de métadonnées, pas des données de pixels. L'extraction de ces balises vous permet de constituer la cohorte, d'exclure les scans incompatibles (par exemple, coupes trop épaisses) et d'assurer la comparabilité.
Les métadonnées vous permettent de surveiller le processus d'imagerie lui-même : l'institution utilise-t-elle le bon protocole ? Les paramètres d'acquisition dévient-ils avec le temps (par exemple, champ de vision, moment de l'injection de contraste) ? Les réglages du fournisseur sont-ils cohérents ? Dans un monde de Big Data où des milliers de scans ont lieu chaque jour, vous ne pouvez pas compter sur une vérification visuelle humaine. Vous avez besoin d'analyses sur les métadonnées. De nombreux systèmes PACS sous-exploitent les métadonnées pour cette raison.
Si vous construisez un pipeline d'IA ou de radiomique, vous ne pouvez pas traiter chaque image comme interchangeable. Les métadonnées deviennent une variable de contrôle intégrale : les caractéristiques d'entrée incluent souvent la modalité, le kVp (pic de kilovoltage), le fabricant, le noyau, l'épaisseur de coupe, et même la date ou l'hôpital peuvent compter (décalage de domaine). Ces champs de métadonnées aident à gérer les biais, à harmoniser les données et à annoter les images avec un contexte. De nombreux chercheurs qualifient les métadonnées « d'aussi importantes que les données de pixels ».
Le Big Data implique une grande échelle. Cela implique des sources variées, de multiples fournisseurs, différentes institutions et des formats hétérogènes. Les métadonnées DICOM sont le « langage » normalisé qui aide à unifier la couche de métadonnées, à permettre la recherche/l'indexation, à assurer l'interopérabilité et à construire des architectures évolutives (Cloud PACS, archives fédérées). Mais la mise en œuvre compte. La même étude PMC a révélé que de nombreux systèmes n'exploitent pas pleinement la norme.
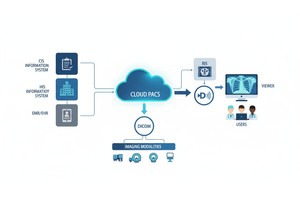
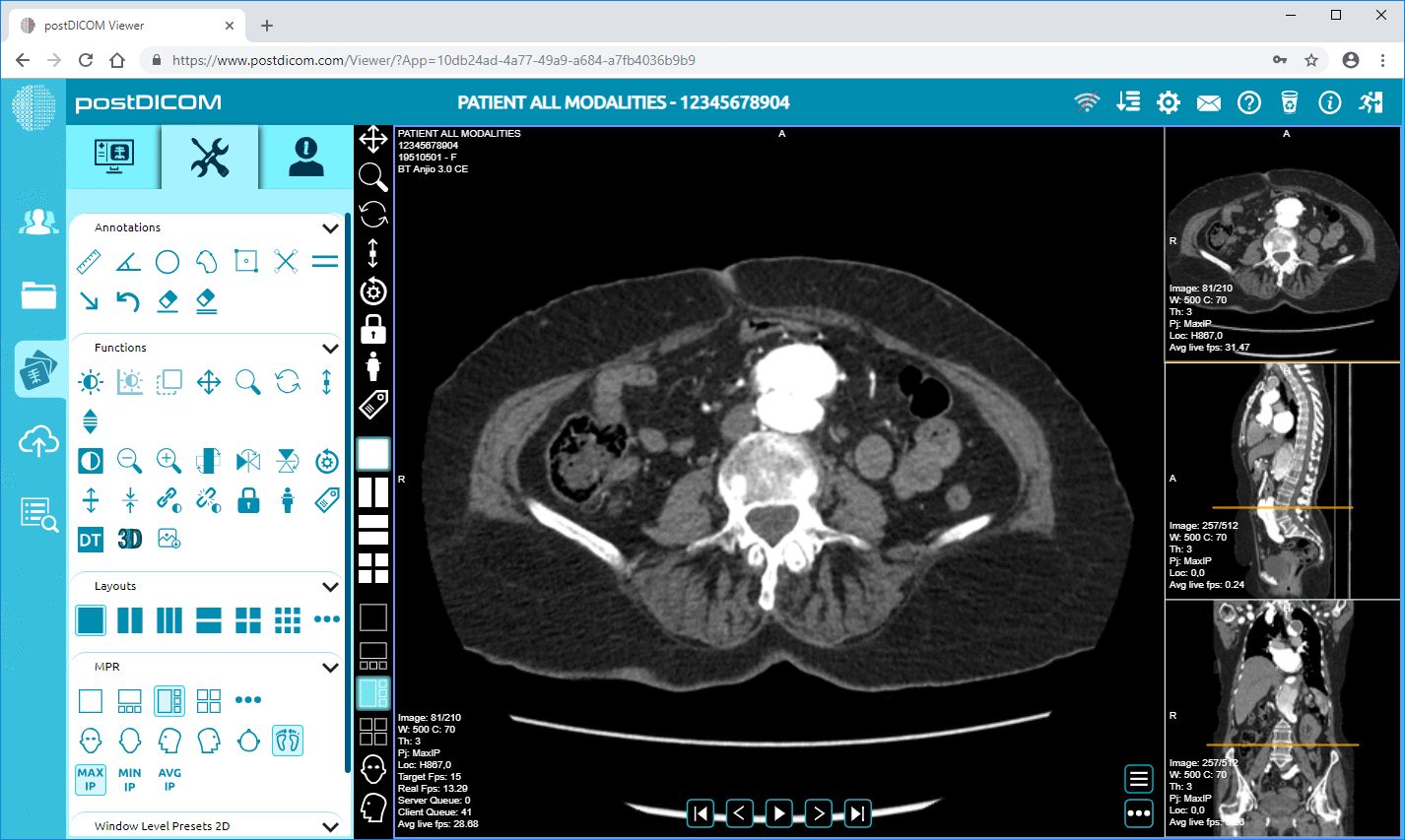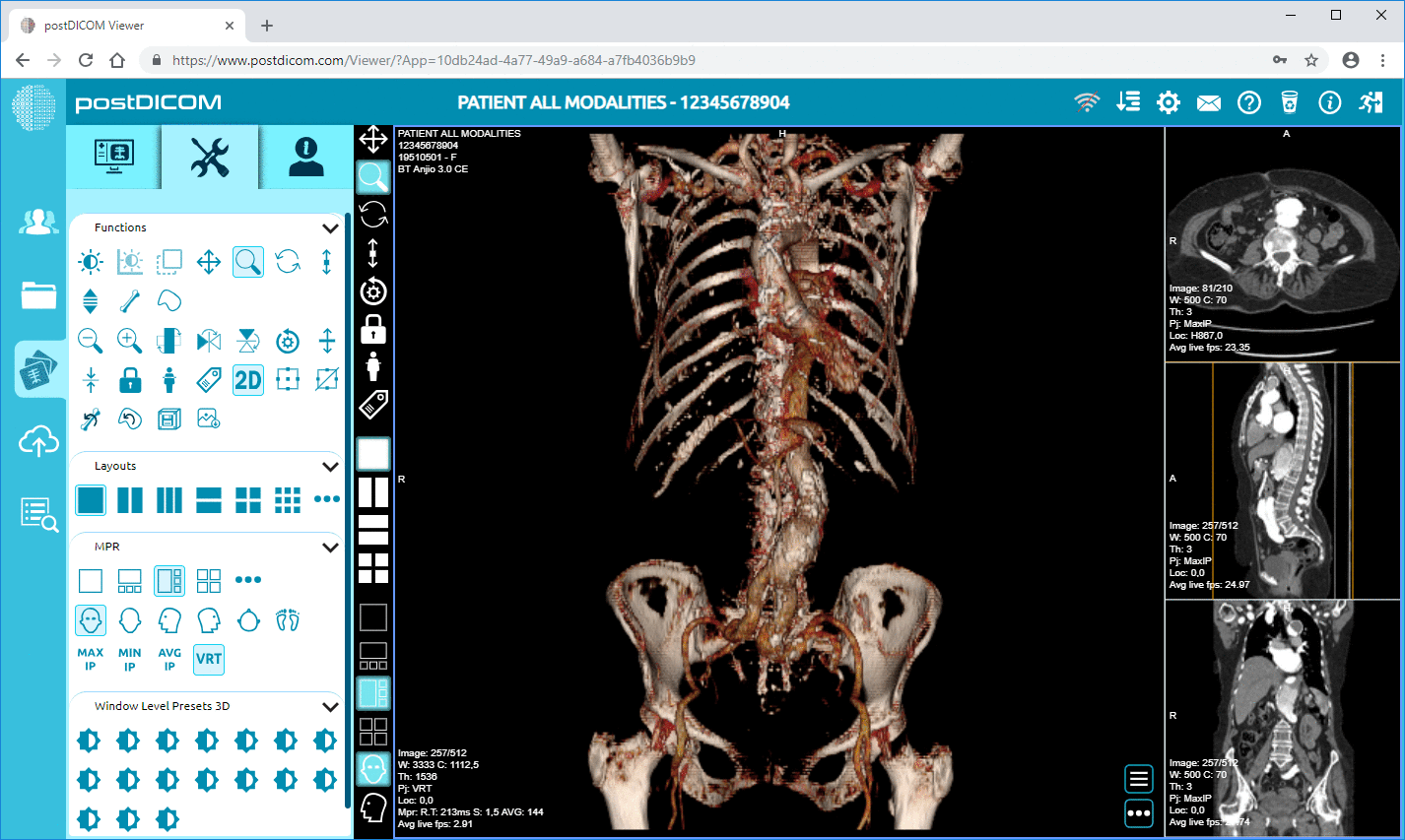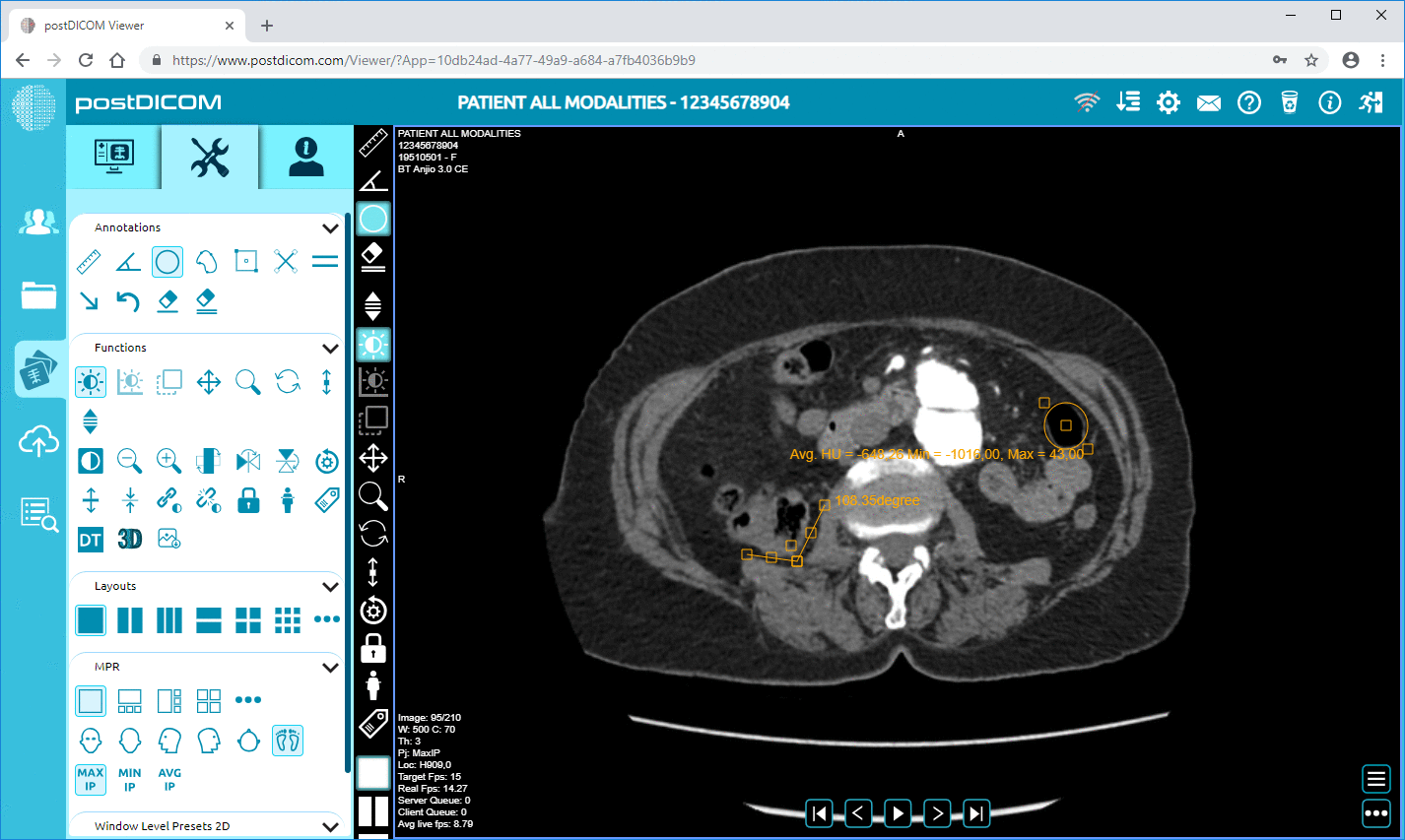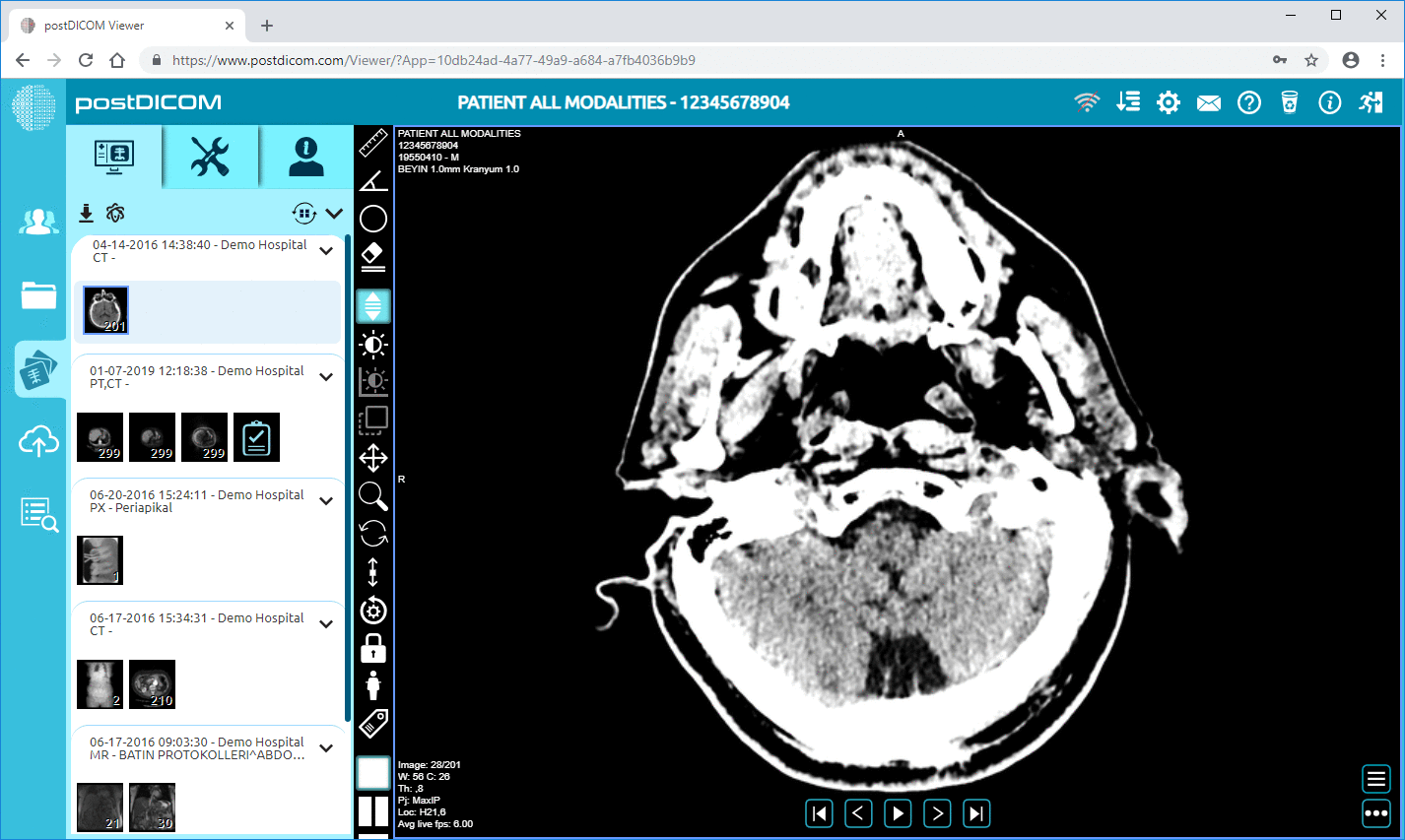
PostDICOM propose un PACS (système d'archivage et de transmission d'images) basé sur le cloud pour stocker, visualiser et partager des études d'imagerie et des documents cliniques. Voici quelques fonctionnalités clés de PostDICOM pertinentes pour les métadonnées :
• Prise en charge des balises et descriptions DICOM : Notre bibliothèque de ressources répertorie « Modalité DICOM et balises », permettant aux utilisateurs d'accéder aux listes de balises et aux descriptions.Modalité DICOM et balises
• Intégration API / FHIR : Elle prend en charge les interfaces API et FHIR (Fast Healthcare Interoperability Resources), permettant aux métadonnées d'être interrogées par programme, intégrées à d'autres systèmes et analysées.
• Évolutivité cloud et partage multi-sites : Partage entre patients, médecins, institutions ; une évolutivité illimitée signifie que les pipelines Big Data deviennent réalisables.
• Traitement d'image avancé et prise en charge multimodale : Bien que cela concerne les pixels, la prise en charge de modalités comme le TEP-TDM et les séries multiples signifie que les métadonnées sont substantielles (valeurs SUV, volumes de fusion, type de modalité) et disponibles pour l'analyse.
L'utilisation d'une plateforme comme PostDICOM vous permet d'exploiter les métadonnées grâce à des flux de travail structurés, des API et une architecture cloud.
Voici comment structurer le flux de travail, des archives brutes aux informations prêtes pour l'analyse.
 - Created by PostDICOM.jpg)
La première étape pour exploiter les métadonnées DICOM à des fins d'analyse est l'extraction et la normalisation. Des bibliothèques telles que le package Python open source PyDicom sont couramment utilisées pour analyser les fichiers DICOM et extraire les balises pertinentes, y compris les lignes et colonnes d'image, les noyaux de convolution et les paramètres d'acquisition spécifiques à la modalité.
La gestion de l'hétérogénéité est cruciale, car différents fournisseurs utilisent souvent des balises privées ou des implémentations non standard. Une analyse robuste, une logique de repli et des tables de mappage de balises complètes sont nécessaires pour assurer la cohérence entre les ensembles de données.
Une fois extraites, les métadonnées doivent être normalisées et mappées à des ontologies et structures standard, telles que les codes de modalité, les noms de fournisseurs, les catégories d'épaisseur de coupe et les formats de date et d'heure normalisés.
Enfin, les métadonnées structurées doivent être stockées dans un environnement Big Data, tel qu'une base de données relationnelle, un magasin NoSQL ou un lac de données en colonnes, avec indexation pour permettre une interrogation rapide et efficace.
Une fois extraites, les métadonnées doivent faire l'objet d'une assurance qualité pour garantir leur exactitude et leur fiabilité. Les champs manquants ou incohérents, tels que les valeurs d'épaisseur de coupe vides, les étiquettes de modalité incohérentes ou les UID d'instance d'étude en double, doivent être identifiés et corrigés.
Confidentialité et anonymisation sont également essentielles à ce stade, car les métadonnées contiennent souvent des informations personnellement identifiables, notamment les noms des patients, les identifiants et les dates ; des outils et des protocoles de désidentification sont indispensables.
Le maintien de pistes d'audit complètes est une autre pratique importante, documentant quand les métadonnées ont été extraites, quelles versions de l'analyseur ont été utilisées et toutes les erreurs rencontrées au cours du processus.
Les politiques de gouvernance doivent également définir les champs obligatoires et fournir des conseils sur la manière de gérer les ensembles de données hérités ou incomplets pour garantir que les analyses en aval sont précises et conformes.
L'étape suivante est l'indexation pilotée par les métadonnées et l'ingénierie des fonctionnalités, qui transforment les métadonnées brutes en informations exploitables.
Cela implique la création d'index et de filtres permettant aux chercheurs et aux analystes d'interroger des ensembles de données spécifiques, par exemple, récupérer tous les scanners thoraciques avec une épaisseur de coupe inférieure à 1,5 millimètre d'un fournisseur particulier dans une plage de dates donnée.
L'ingénierie des fonctionnalités s'appuie sur cela en combinant des champs de métadonnées tels que le fournisseur, le modèle, la date d'acquisition, l'épaisseur de coupe, le noyau de convolution, le protocole de contraste, la région du corps, la dose de rayonnement et l'identifiant de l'institution en variables structurées adaptées à l'analyse.
Les métadonnées peuvent également être liées à des ensembles de données cliniques, reliant les données d'imagerie aux résultats, diagnostics ou traitements des patients. Ce lien permet une vision plus holistique des données d'imagerie et de leur contexte clinique.
Une fois les métadonnées indexées et les fonctionnalités conçues, l'analyse et la génération d'informations deviennent possibles.
L'analyse descriptive peut révéler les volumes d'études par modalité, fournisseur ou région, suivre les tendances des paramètres d'acquisition et mettre en évidence les erreurs ou les incohérences dans les pratiques d'imagerie. L'analyse comparative permet d'évaluer les protocoles d'acquisition entre les institutions, de détecter les déviations et d'identifier les examens aberrants qui peuvent nécessiter une attention particulière.
Pour les applications d'apprentissage automatique et d'IA, les métadonnées sont essentielles pour contrôler le décalage de domaine, garantir que les ensembles de données de formation et de test sont stratifiés de manière appropriée et combiner les caractéristiques basées sur les pixels avec des variables de métadonnées structurées. Les tableaux de bord opérationnels peuvent ensuite exploiter ces données pour surveiller la charge de travail, évaluer les mesures d'assurance qualité et assurer la conformité aux protocoles sur les sites.
Enfin, la rétroaction et l'amélioration continue complètent le cycle de vie des métadonnées. Les informations dérivées de l'analyse peuvent éclairer l'affinement des protocoles d'acquisition et la normalisation des flux de travail pour améliorer la qualité globale des données.
De nouvelles études d'imagerie et métadonnées doivent être ingérées en continu, avec une surveillance des performances du magasin de métadonnées, des temps de requête et de l'intégrité des données. Les leçons apprises doivent être archivées pour capturer des champs de métadonnées prédictifs, combler les lacunes ou erreurs récurrentes et améliorer les pratiques de gouvernance.
Cette approche itérative garantit que les pipelines de métadonnées restent robustes, évolutifs et précieux pour la recherche future, les applications d'IA et la prise de décision opérationnelle.
• Variabilité des fournisseurs/institutions : Balises privées ou interprétations vagues des normes.
• Métadonnées manquantes ou corrompues : Les études plus anciennes peuvent avoir des en-têtes incomplets.
• Confidentialité des données et anonymisation : Les informations de santé protégées (PHI) doivent être désidentifiées pour la recherche multi-sites.
• Échelle et performance : Des millions d'images nécessitent un traitement et un stockage efficaces.
• Décalage de domaine/biais : Les fournisseurs/protocoles dominants peuvent fausser les modèles d'IA.
• Questions réglementaires et de conformité : Les déploiements multi-régions peuvent impliquer la HIPAA, le RGPD ou les réglementations locales.
Les métadonnées DICOM sont le squelette caché de l'analyse d'imagerie. Des plateformes comme PostDICOM illustrent comment transformer une archive fragmentée de fichiers DICOM en un écosystème consultable, évolutif et piloté par les métadonnées. Si vous souhaitez explorer PostDICOM, nous vous encourageons à profiter de notre essai gratuit de 7 jours.